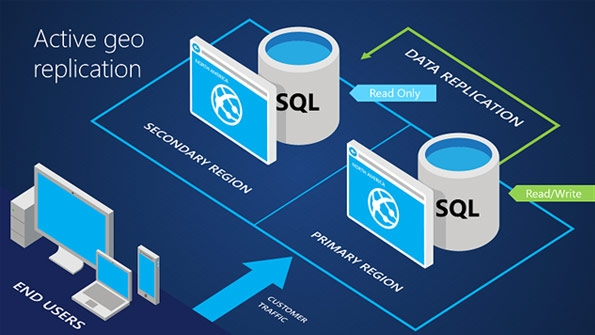
Image 1: Azure SQL Database Geo-Replication
On the PRIMARY LOGICAL SERVER:
STEP 1: ON THE PRIMARY MASTER DATABASE - CREATE A NEW LOGIN:
--NOTE: Logins do not get automatically synced from PRIMARY TO SECONDARY(s)
CREATE LOGIN dbuserxyz
WITH PASSWORD = 'insertstrongpassword'
GO
STEP 2: ON THE PRIMARY USER DATABASE: CREATE A NEW USER
--NOTE: Users do get automatically synced from PRIMARY TO SECONDARY(s)
CREATE USER dbuserxyz
FOR LOGIN dbuserxyz
WITH DEFAULT_SCHEMA = dbo
GO
STEP 3: ON THE PRIMARY USER DATABASE: GRANT PERMISSIONS
EXEC sp_addrolemember N'db_owner', 'dbuserxyz'
GO
STEP 4: GET PRIMARY LOGIN SID:
STEP 4(a): ON THE PRIMARY MASTER DATABASE:
SELECT [name], [sid]
FROM [sys].[sql_logins]
WHERE [type_desc] = 'SQL_Login'
STEP 4(b): ON THE PRIMARY USER DATABASE:
SELECT [name], [sid]
FROM [sys].[database_principals]
WHERE [type_desc] = 'SQL_USER'
Once you have the matching SID from the Login and it's User, copy that for the step below.
ON THE SECONDARY LOGICAL SERVER:
STEP 1: ON THE SECONDARY MASTER DATABASE:
CREATE LOGIN dbuserxyz
WITH PASSWORD = 'usesamepasswordabove', SID = 0x01000064000000000000003EE347F04C9F4A903BC9B9
go
At this point, the Login and User are fully configured on THE PRIMARY and SECONDARY Nodes. In the event of a failover from PRIMARY
to SECONDARY, which typically takes 1-5 minutes for our 1GB database, the access & permissions will be there for that login & user.
However, the webconfig must be updated to point to the new Primary Read/Write Node. Your development team could code exception handling
for a failover and allow it to connect to the target failover server in the webconfig. Remember, currently only one Node (Primary) is a
Read/Write node and all the others are Read nodes.
Resources:
How to manage Azure SQL Database security after disaster recovery
Overview: SQL Database Active Geo-Replication
Azure SQL Database
|
|
|
|
|
|