AlwaysON Availability Groups - Data Synchronization Process
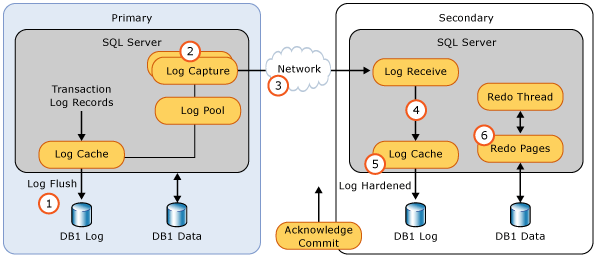
SQL Server does not ship transactions. It ships Log Blocks. (Not replicating Commits – Log Blocks are the Replication Unit)
A Database's Transaction Log maps over one or more physical .LDF files. Each .LDF file is then broken into a number of VLF files. VLF's are then divided into Log Blocks. Log Blocks are containers for Log Records. (all of these items are managed by the Log Manager)
- The Transaction Log file is with wrap-around nature. This means that whenever we reach the end of the file, the engine will try to reuse the first VLF. If this is not possible, and auto-grow is enabled, SQL Server will try to grow it.
- Log Blocks are between 512 bytes and 60 kilobytes large. These are respectively the smallest and largest amount of data that can be flushed to disk by the Log Writer.
- In SQL Server, almost every operation is logged. Data modifications/DML(insert, update, delete), page allocation/deallocation or the beginning and end of a Transaction, etc. The database engine is recording these changes by creating Log Records for it. Each Log Record is identified by a unique number called LSN(Log Sequence Number). The LSN number is increasing so the next Log Record will always have a higher LSN than the previous one. LSN is 10 bytes in length and it is consisting of three parts: VLF Sequence Number (4 bytes): Log Block Number (4 bytes): Log Record Number (2 bytes).
- Transactions are reflected into the Log as a chain of Log Records. Log Records are stored in a serial sequence as they are created so the LSNs that are part of the same Transaction are not necessarily located next to each other. Each transaction has an ID that is pointed in every Log Record. SQL Server is using this to create a chain using backward pointers in order to track all the LSNs that are part of a specific transaction and speed up the rollback process.
fn_dblog allows us to examine Log Records.
Log records are first stored in the Buffer Pool and then they are flushed to disk in one of the following events:
- If Commit/Rollback a Transaction
- If Log Block hits its maximum size of 60 KB
- If a Data Page is being written to disk – all the log records up to including the last one affecting this page must be written to disk regardless of which transactions they are part of.
Solution:
Select --n.group_name as 'AG_Name', n.replica_server_name as 'Replica', n.node_name as 'Node',
cs.replica_server_name as 'Replica Name',
rs.role_desc as 'Role',
rs.connected_state_desc as 'Connected State', ar.availability_mode_desc as 'Availability Mode', ar.failover_mode_desc as 'Failover Mode',
db_name(drs.database_id) as 'DBName', drs.synchronization_state_desc as 'synch_state_desc', drs.synchronization_health_desc as 'synch_health_desc', cs.join_state_desc,
DATEDIFF(MS,LAG(drs.last_commit_time) OVER(PARTITION BY drs.database_id ORDER BY drs.database_id DESC),drs.last_commit_time) AS RTO_ms, drs.last_commit_time,
drs.last_redone_time as 'last_redone_time_logrecord_sec', drs.last_hardened_time as 'last_hardened_time_logblock_lsn_sec',
drs.last_received_time as 'last_received_time_logblock_sec', drs.last_sent_time as 'last_sent_time_logblock', drs.last_hardened_lsn,
drs.last_redone_lsn, drs.recovery_lsn
from --sys.dm_hadr_availability_replica_cluster_nodes n
--join
sys.dm_hadr_availability_replica_cluster_states cs --on n.replica_server_name = cs.replica_server_name
join sys.dm_hadr_availability_replica_states rs on rs.replica_id = cs.replica_id
join sys.dm_hadr_database_replica_states drs on rs.replica_id=drs.replica_id
left join sys.availability_replicas ar on ar.replica_id = rs.replica_id
order by db_name(drs.database_id) asc, rs.role_desc asc

sys.dm_hadr_availability_replica_cluster_nodes
sys.dm_hadr_availability_replica_cluster_states
sys.dm_hadr_availability_replica_states
sys.dm_hadr_database_replica_states
sys.availability_replicas
sys.availability_group_listeners
Resources:
How It Works: Always On–When Is My Secondary Failover Ready?
|
|
|
|
|
|